Watch out! Trapping comfort won't let you flit to your next goal! Experiences of a Tech Junkie, self taught artist and his craving for new experiences. Opinions are personal. Content published is not read or approved in advance by any company and may not reflect the views and opinions of my employer or any of its divisions, subsidiaries, or business partners.
Let’s say you need a more scalable layer-2 solution for your VMs and containers. You can do some Linux bridges or maybe use OVS and try some VxLAN/GRE encapsulation between Hypervisors. Containers is a different kind of animal though: Way more end-points in every server and we put them across the datacenter, it could turn into the worst nightmare if you need to troubleshoot it.
DevOps or IT guys, that normally try the network as a black box to connect end-points. And still think that hardware appliances can be replace for modules in the kernel (I used to be one of them). It’s important also to say that sort of thought could fit in Enterprise use cases, but a Telco cloud, VNFs, CNFs, is in other league.
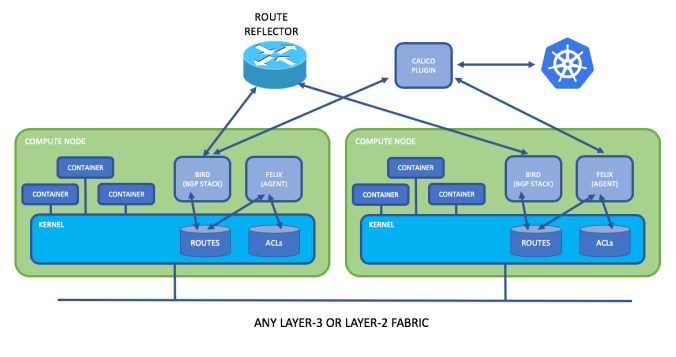
Calico is great solution that work over pure Layer-3 approach. Why? Well, they say that “Layer 2 networking is based on broadcast/flooding. The cost of broadcast scales exponentially with the number of hosts”. And yes, they are absolutely right… if you are not putting something like EVPN (RFC 7209) to help you out on building Layer-2 services of course.
Calico Kubernetes Architecture
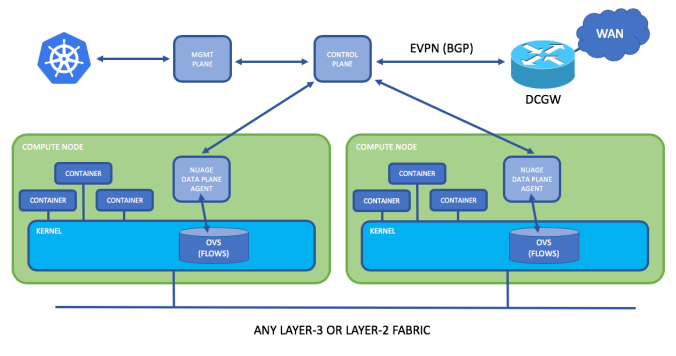
EVPN don’t rely on flooding and learning like other technologies, actually uses control plane to advertise MAC addresses across different places. They can say: “Well, you will be using encapsulation that also have an important cost”… Well, yes and no. EVPN can use different data planes actually (i.e. MPLS). Maybe Nuage uses VXLAN, but it’s not limited by the technology to use other sort of transportation.
Also, scale can kill any good idea. Like rely on Linux kernel modules and services to route all communications in the datacenter. Try every server as a router? Create security policies for every end-point in the DC? Uff! For example Calico took the idea from the biggest network ever known today. Yes! the Internet. But it doesn’t mean this network is optimal. Many companies needs to rely on MPLS or other sort of private WAN services for higher demand in security and performance.
Nuage and Kubernetes Architecture
Layer-2 services help to simplify network design and security. Some Layer-2 domains don’t need to connect to any Layer-3 for security reasons. Also, Layer-2 domains in the datacenter can be directly attached to a Layer-2 service in the WAN (i.e. VPLS, MPLS). We can add many more things on the list like Private LTEs, Network slicing…
EVPN benefits
EVPN came as an improved model from what is learnt in MPLS/VPLS operations. Also, it’s a join work of many vendors as Nokia (former ALU), Juniper and Cisco. MPLS/VPLS relies on flooding and learning to build Layer2 forwarding database (FDB). EVPN introduced a new model for Ethernet services. EVPN uses Layer-3 thru MP-BGP, as a new delivery model, to distribute MAC and IP routing information instead of flooding and learning.
In summary key benefits we can export to CNF/VNFs use cases:
Scalability: Suppress unknown unicast flooding since all active MACs and IPs are advertised by the leaf or the software router you have installed in the hypervisor.
Peace of mind: Network admin will have a better control on how the cloud instances escales avoiding issues regarding flooding or loops or MAC mobility/duplications. And cloud admin will keep provisioning and moving around instances with minimal concern o the impact they can cause on the network and reducing the overhead regarding the setup of layer-2 services.
Workload mobility: If local learning is used, software routers can not detect that MAC address has been moved to other Hypervisor or Host. EVPN uses a MAC mobility sequence number to select always the highest value and advertise rapidly any change. Also the local software router to the Hypervisor will always respond to ARP request for the Default Gateway, that avoids tromboning traffic across remote servers after a MAC moves.
Ready to work with IPv6. EVPN is ready to manage IPv4 and IPv6 in the control and data plane.
Industry standard: software router can be directly integrated with Layer-2 services to the WAN thru Datacenter Gateways efficiently advertising MAC and IP routing from VM and containers. Some VNF/CNF are very complex communication instances that require to work directly with ethernet services. It can be seen as a no better seamless and standard solution than EVPN. Some of you can tell me Segment routing can be a better fit… Agree. Great material for “later” post though.
Resiliency: Multi-homing with all active forwarding, load balancing between PEs. Don’t waste bandwidth with active and standby link. You can create a BGP multi-homed subnet to the datacenter gateway (DCGW) form any virtual workload.
Relevant technologies like DPDK or SmartNICs are starting to come up lately to bring better performance options to CNF/VNF instances. Sharing a Linux kernel among other applications, is not good enough for some network functions. However, there are still other options before considering replacing your hardware.
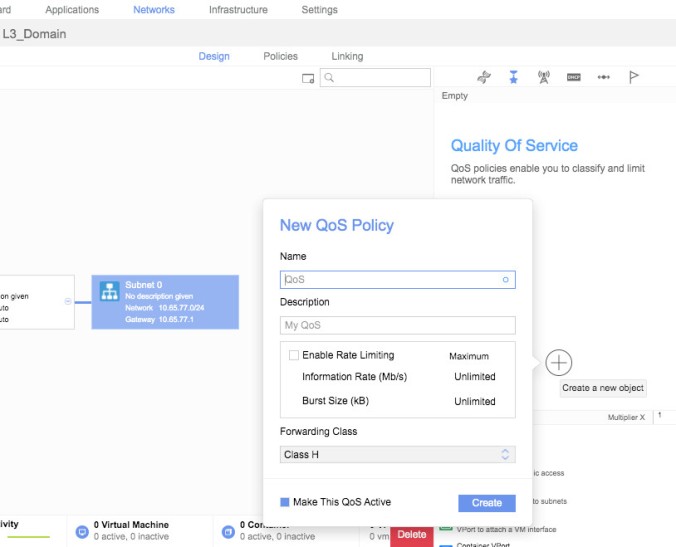
Quality of Service (QoS) could be the cheapest and quick way to solve some scale issues. Or unless it will give you a better understanding of what sort of traffic you’re dealing with, or help you to avoid any fight over resources with traffic managed from IP Stack for KVM, management or Storage.
QoS sounds like the right path to follow for a network professional, but unnatural for IT guys or DevOps. If you combine those skills, that would bring an easy and fast way to deploy QoS policies at big scale, and the power to adapt them much faster to changing conditions (i.e. market, covid, weather…)
CNF/VNF vs Network Infrastructure
OpenStack is being popular in Telco to orchestrate network functions. And along with that, different sorts of requirements have come up from the network. A VNF can be a bunch of VMs with different demands. Network traffic to/from those VMs can be managed through an OVS at the kernel, fighting for resources with other applications between kernel interruptions.
VNF traffic could be diverse, and some packets should be treated and forwarded faster. But if you don’t do anything, small critical packets (i.e. network control) will be treated as any sort of traffic, and they could be waiting for their turn after some big non-critical file transfer that maybe doesn’t have anyone urgently waiting on the other side.
There are hardware options like DPDK, off-load NICs or SR-IOV. They are more expensive and require specific pieces of software to manage them. SRIOV works passing-through OVS in the kernel and that would bring a higher challenger for orchestration to keep the so demanded agility. This won’t avoid you the fuss of designing appropriate QoS policies. Resources are limited, no matter what magic you do.
5G and CNF won’t make things easier. The density of end-points per server has grown exponentially. And if VMs could still be managed thru VLANs, command-line and QoS policies over a traditional fabric. CNF will force you to automate and orchestrate those policies through APIs and group policies based on metadata. Containers are state-less and change their IP address on every reboot. And sorry, you can’t skip QoS, best effort or FIFO approach from kernel modules is not good enough anymore.
Let’s check some QoS concepts in the following section
Common QoS Mechanisms
Quality service is more a collection of tool that just one thing. And the following are the categories of those tools.
Classification and Marking (i.e. DSCP): Before entering the network, some packets will be classified and marked to make their identification easier just reading the header for any later switch/router or virtual router involved on the forwarding process. That will make things more efficient in time and resources. There’s a point where you don’t know if the packet will stay in the DC or will be sent outside through MPLS to another DC. Apps will be able to flow anywhere.
Queueing: every router will manage different “buckets” for different packets that have been identified using the marks we told before, in the buffer for queuing and wait to be forwarded. Of course, packets classified with higher priority will be forwarded accordingly to their priority. SDN usually relies on queues which are defined in the NIC and mapped back to the tap interface of VM where the packets are marked before to be forwarded anywhere.
Congestion avoidance: If that buffer gets full at the network card, then packets will start to get dropped. Tools like RED will avoid that sort of issue by dropping random packets.
Policing (drop) and shaping (hold): Traffic conditioning, set a speed limit, maximum of bandwidth. Policing drops the traffic and shaping hold the traffic until packets can be sent staying inside the limits of speed.
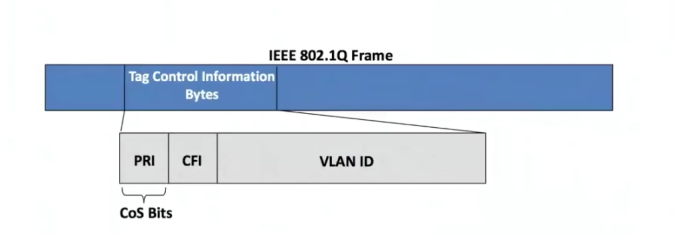
Classification and Marking (DSCP)
Class of Service (CoS)
There are bits you can use to define a CoS in every frame header. Then you can have 8 values (0 to 7). Vendors like Cisco leave the value 6 and 7 for other purposes. Then, It’s better to use values between 0-5. Cisco mark some of the packets for their VoIP products by default with the value 5.
Class of Service – CoS
Because it’s a Ethernet datagram, then you will run into issues with CoS when they go through a router, cause they will re-write the headers and then you might lose what was define.
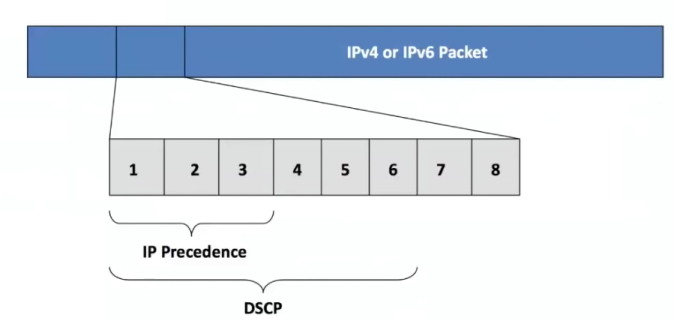
Type of service (ToS) Byte
A byte in the IP packet header will carry the Type of Service (IPv6 call it Type of Class). You may use the three left bits in this section to identify your type of service. Those bits are used for the IP precedence marking. You may not use the values 6 and 7 like we said before, because those are still used to identify the CoS like we showed for datagrams.
If we add the next three bits of the byte, we expand the amount of values for a classification from 8 to 64. A more realistic number for nowadays, don’t you think? Those 6 left bits in the byte is what we call DSCP (Differentiated Services Code Point).
IPv4 Type of Service or IPv6 Type of Class Byte
We have values between 0-63 (64 possible values like we said). To make things easier IETF set a standard of which values you could use and stay in sync with the rest of the world. They set 21 values. IETF gave them names and they call that Per hub behaviors (PHB). The two most important values to remember are:
Default: 000000
Expedited Forwarding: 101110
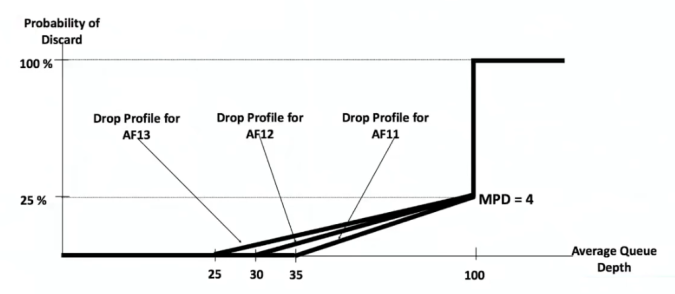
Next table will show the Assured Forwarding (AF) values. It’s important to mention that the dropping priority is independent of the class. Then, in case the buffer gets full and some packets need to be dropped, AF22 will be dropped before AF11. it doesn’t matter, it has higher priority on forwarding. Be careful selecting your values.
DSCP Assured Forwarding Table
Random Early Detection (RED)
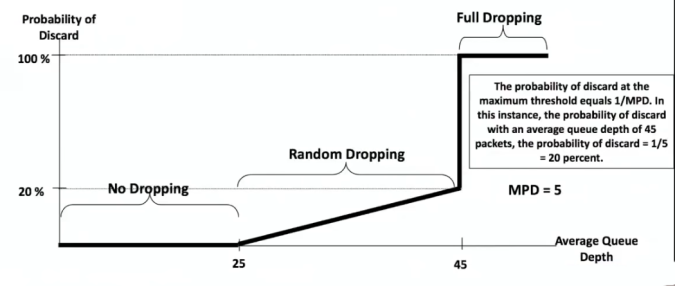
Now that we are talking about packet dropping. Then it’s important to talk about RED. RED is the industry standard for dropping packets. Eventually your router will do it and the question is how that will be managed. RED defines a Maximum threshold that when it is hit, it’s a 100% probability that queue will drop that traffic.
RED packet dropping
A better way to see it’s using the next picture. As an example we have a queue with 45 packets as average queue depth. before to reach 25 packets, there’s no dropping. After 25 the line is smoothly introducing the probability of discard packets until reach the 45, where the probability goes from 20% to 100%.
You can set those thresholds and MPD (mark probability denominator). MPD will define the probability at where the random dropping will work before to reach the Maximum threshold. And for your information, none ever try to touch those values. Unless you have a very specific use case.
Now, Cisco varies that probability depending on the Class of Service, defining RED profiles for each AF value.
WRED drop profile depending on Class of service
Explicit congestion Notification (ECN)
If you remember we talked about ToS and the bits regarding DSCP. Ok, and what about the last 2 bits i the ToS Byte? Those bits, basically, are use to notify the origin router that the queue is full or congested and ask it to slow down. Then, if the router send 11, means it’s experiencing congestion and other route should be considered.
This is more informative. I didn’t want to let that gap i this overview. We won’t talk of this in CNF/VNF use cases.
Traffic Policing vs. Traffic Shaping
Well, a decent SDN solution should also offer Traffic Policing and Traffic Shaping. The idea is to understand the difference between both.
Some SDN software applies it only for the traffic which goes from VM to Network, around the VM’s tap interface. Others must be enforced directly in an external switch/router hardware piece thru the identification which VM is sending that packet thru some way. but. again, depends on the technology/vendor.
Traffic Policing
Traffic policing is more regarding a limitation in Bytes over a certain period of time. We have two important values:
Committed Information Rate (CIR) which is the average speed that the Network guarantees the VM’s port or container’s port
Committed Burst (Bc): which defines the amount of packets (usually in bytes) that can be sent as a group without causing any violations or exceeding the CIR.
Let me illustrate this with the following example:
Let’s say the average speed or CIR will be 200Mbps and we allow a Bc of 20MB. Then, the VM sends an initial bunch of packets for a total of 9.6MB. We have 10.4MB or 10.4M tokens left in the bucket. If we sent another burst 0.1s (100 msecs ) later. What would be the limit we have to avoid any packet delay or drop? The answer is 12.9MB maximum. Why? because we have 10.4 left plus the 2.5MB added after 0.1s based on the following formula (0.1s*200Mbps/8bits):
Traffic Shaping
Now, let’s do the same with traffic shaping:
Now we have other value call Traffic Interval (Tc)
We have 200Mbps on a 1Gbps virtual interface. and we want to set a Tc of 125ms. means we can send 25Mbps every 125ms. In this case, the enforcement is you can fill a bucket up to 25Mbits every 125ms, the rest of the packets could be dropped or delayed. However, those 25Mbits of data will be sent at “line speed” and the bucket could be emptied long before to reach those 125ms limit. Then, you can have a behavior like is shown in the next picture..
QoS in a CNF/VNF Telco Cloud Setup
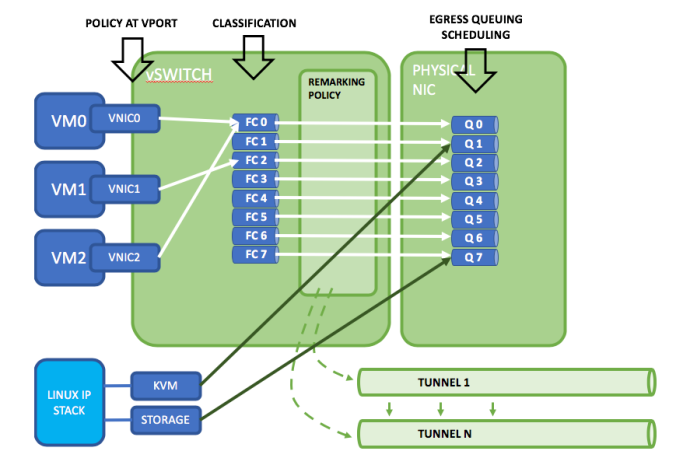
Instances like VNF and CNF commonly run on KVM and Docker Engine respectively. Either way, KVM or Docker will use Linux IP Stack to send traffic and let the kernel decide in what network resources are used to ensure priority in their common tasks. For example, KVM uses specific queues in the NIC for some traffic like storage or management. The configuration commands on how to configure the egress queue scheduling as well as kernel mappings, etc. are highly dependent on the distribution of Linux used on the hypervisor as well as the specific physical NICs and the driver version.
Nuage QoS Classification, NIC queues, Forwarding Class and Kernel
Nuage uses a management plane to manage multiple control planes with XMPP. VSD can be accessed through a GUI or APIs to define QoS policies at vport, subnet, zone or domains (i.e. VRF).
Nuage forwarding class and traffic shaping in VSD
Nuage, for the VMs that use OVS with a VirtIO driver, uses 8 classes and binds every class to a different queue in the server NIC. You can mark traffic going into the network. However, traffic arriving to the VM is not affected, basically it is not worthy, the packet is already on the server.
Also, in the previous image you can see you can define Traffic Shaping policies also at different levels in the domain.
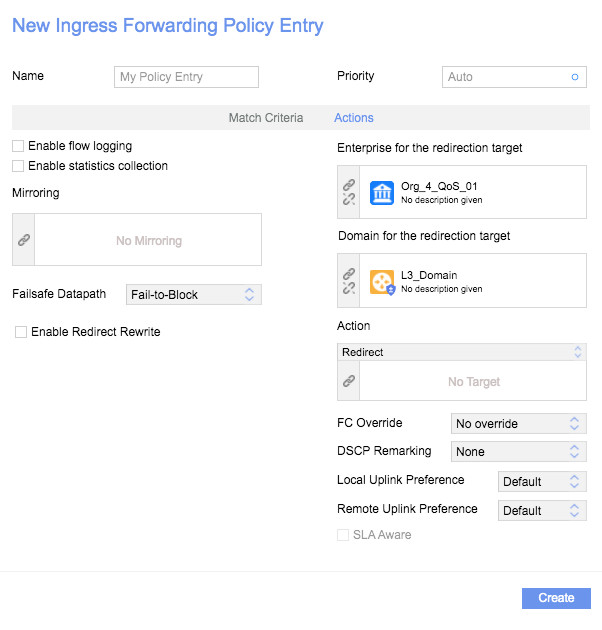
Also, depending on the SDN software, you will find different ways to deal with DSCP marking or traffic shaping. For example, you can define a specific policy based on TCP or UDP traffic.
DSCP marking in Nuage through a QoS policy based in specific TCP/UDP traffic or former DSCP mark (only for Traffic from VMs to Network)
Hope that explanation worked for you. You can check the references for more details though.
I’ve been working more than two years in Nuage Networks traveling all around Americas (North, Central and South. And BTW, Mexicans are North-Americans. Please, don’t tell me otherwise. ok? ). Now, we have SDWAN initiatives thru Local Operators, Service Providers and Startups all over.
On the beginning, almost all my actions were related to promote and show how SDN can make things simpler and faster at the Datacenter. Techs like OpenStack and Docker where my entry point into any opportunity. Besides most of companies are still stuck with VMware. Customers want to lower costs and take advantage of orchestration. However, There’s big thing to sort out first… “the network”. Besides projects like Neutron and Dockers, Companies still have so much to do to make them work widely.
Nuage can manage any kind of workload at the datacenter, either public or private ones. It can help to make that transition much faster and smoother.
Over the last year I’ve been putting more and more hours into SDWAN though. Why? Let’s blame the instant gratification… or Smart Phones, Moore’s law.
An important factor is Telcos (a.k.a. Service Providers) have a huge delay on matters of Innovation (i.e Orchestration). On the other hand, customers are more hunger than ever for a more reliable, agile, affordable service.
Other reason is because Internet has many times more coverage, better price and reliability than a few years ago. Services as Spotify, Amazon video and Netflix are showing us that to download an App is much cheaper and faster than waiting for the TV cable technician to show up. Or are you still using a separated cable for each TV, Phone, Internet service at home?
Services Providers should seize the opportunity instead to see how to protect their current network.
Service providers, for companies like us, are a big pay-check opportunity. We’re helping some of them to develop new services on top of SDWAN. However, what is the rush for most of them? They actually did, over the end of the “last century”, a big investment for their MPLS network. They are getting more profit over-subscribing it.
Companies like Banks and Retails are tired of that. Waiting months to get services configured. Paying every month fortunes for a MPLS service that actually sucks. How much revenue won’t you get for waiting to have your branch connected? They haven’t known any other option until SDWAN came up.
SPs are still thinking on SDWAN as a cheap CPE box they used to install at branches. When SDWAN is putting all the intelligence over the end-points. Making the Network devices irrelevant when a VPN is stablished. Customer will have “absolute” visibility over every uplink performance. Managing better redundancy between two links attached to “different” networks (i.e. a MPLS and Internet). They can even switch paths for their Apps based on jitter information and thresholds.
Some local Operators has seen it. Even when they have a “huge” disadvantage over known Service Providers cause their tiny or non-existant network infrastructure. They don’t have a huge investment to protect. They can be more creative on what services to bring on top of it. Bringing “premium” private networks to enterprises not owing a piece of cable. Something as Uber bringing transportation services not owing the cars.
Just ping me and let you know who is actually offering that in your location 😉 or if you want to be become one of those visionaries.
Sure you’ll find this post very useful. A very good feature on Nuage is you can replace the sh*** metadata proxy service in Neutron with nuage-metadata-agent. However, it’s not a easy way to test it and check if working ok. Nuage is running that agent on every compute server and it’s taking all request directly to nova metadata service at port 8775. Then, Neutron is not taking part on that process never more. That way, Nuage remove single-points of failure and reduce the complexity.
Configure your Nuage Metadata Agent
Ok, connect to your Nova controller and check the /etc/nova/nova.conf file and look for the following:
Now install your nuage-metadata-agent RPM package regarding Nuage version you’re using on every compute and configure /etc/default/nuage-metadata-agent file as follow:
If you are using CentOS, restart openvswitch service. And you are done!
Test your access to metadata nova service
If you are having issues, Maybe you should try first check credentials
Create on any compute server the following file called token-request.json (remember replace the values with your actual ones):
if you get token, the you’re fine and then you can go to the following step
Now, check access to port 8775 at nova controller. You should get something like this:
Mostafa. Thanks very much. Nice job. This is important update how Containers works with Nuage. Seems also a more clean way that before. Using –driver –ipam-driver brings network details from nuage we couldn’t got before.
The Nuage libnetwork plugin allows users to create new networks of type Nuage. Nuage libnetwork plugin runs on every docker host. Each Docker host, whether bare-metal or virtual, also has the VSP’s Virtual Routing and Switching (VRS) component installed on it. VRS, a software agent, is the Nuage user space component of standard Open vSwitch (OVS). It is responsible for forwarding traffic from the containers, performing the VXLAN encapsulation of layer-2 packets, and enforcing security policies. When creating a Docker container, the user can specify what Zone or Policy Group it belongs to. All endpoints in a given Zone adhere to the same set of security policies. Nuage libnetwork plugin supports built in IPAM driver where the IP address management is done by VSP.
The libnetwork plugin supports both local and global scope networks. The scope defines if your network is going to propagate to all the nodes as part of your cluster…
Provide an Ansible playbook that implements the steps described in Installing Kubernetes on Linux with kubeadm for version 1.5 (check at the bottom of the kubeadm tutorial). My case, ansible runs into a container with a temporary private key.
Full network connectivty exists between the machines, and the Ansible control machine (e.g. your computer)
The machines have access to the Internet
You are Ansible-knowledgable, can ssh into all the machines, and can sudo with no password prompt
You have access to your Nuage VSD and VSCs from any server with no restrictions
Make sure your machines are time-synchronized, and that you understand their firewall configuration and status
Ansible Inventory Structure and Requirements
Define an Ansible inventory group for each Kubernetes cluster you wish to create/manage, e.g. k8s_test
Define two Ansible child groups under each cluster group, with names _master and _node, for example k8s_test_master and k8s_test_node
List the FQDN of the machine assigned the role of Kubernetes master in the [cluster_name_master] group.
List the FQDNs of the machines assigned the role of Kubernetes node in the [cluster_name_node] group.
Optionally add the variable master_ip_address_configured in the [cluster_name_master:vars] section, if your master machine has multiple interfaces, and the default interface is NOT the interface you want the nodes to use to connect to the master.
A sample Inventory file called k8s-hosts is included, but if you have/use an existing Ansible inventory, it is a lot easier to just add the structure described above to your existing inventory.
After you have done this, you should be able to succesfully execute something like this:
If you want to interact with your cluster via the kubectl command on your own machine (and why wouldn’t you?), take note of the last note in the “Limitations” section of the guide:
There is not yet an easy way to generate a kubeconfig file which can be used to authenticate to the cluster remotely with kubectl on, for example, your workstation. Workaround: copy the kubelet’s kubeconfig from the master: use
scp root@:/etc/kubernetes/admin.conf .
and then e.g.
kubectl --kubeconfig ./admin.conf get nodes
from your workstation.
The playbook retrieves the admin.conf file, and stores it locally as ./cfg/cluster_name/admin.conf to facilitate remote kubectl access.
Additional Playbooks
ansible-playbook -i k8s-hosts -e cluster_name=nuage_k8s nuage-cluster-1.5-destroy.yml
Completely destroys your cluster, with no backups. Don’t run this unless that is what you really want!
Notes and Caveats
This playbook is under development and not extensively tested.
I have successfully run this to completion on a 3 machine CentOS setup, it basically worked the first time.
Network Services Gateway (NSG) is the Nuage SD-WAN product that comes in many forms. In this blog we’ll talk about how to bootstrap a Virtual NSG for KVM using an .iso file, or Zero Factor Bootstrap (ZFB). ZFB is one of three bootstrap methods. The other two require human intervention via email (single) or email plus SMS Text (dual).
I was going to start listing prerequisites which I typically post but realized that there really aren’t any. Since the .iso file can either be placed on a USB stick or mounted using either ESXi or KVM the options are really open as to how you want to utilize it.
In this article we’ll use the following to bootstrap an NSG
.iso file with NO USB stick required
CentOS KVM host simulating a server at a remote location (Branch1)
Static IP Address for both MPLS and Internet facing ports from the NSGv
In this post we’ll learn how to install OpenStack RDO (Newton) and integrate it with nuage. As a perquisite the Nuage VCS components must have already been installed and setup. The only requirements between the OpenStack controller and the VSD is that the root (or whatever user you plan to utilize for API access between the OpenStack Contoller and the VSD) be placed within the CMS User Group which is found under:
Platform Configuration” –> “Settings” –> “User Group
Outline of things to do
Prepare the OpenStack Controller
Prepare the answers file
Prepare the OpenStack Compute Nodes
Run the PackStack answers file
Clone the bash scripts and run
RDO (PackStack) Newton installation with Nuage VCS 4.0R8
Preparing your OpenStack (PackStack) Controller
LAB Setup to deploy RDO OpenStack Newton with the following requirements 1 OpenStack Controller
2 Nova Compute Nodes
NFS Server (Nuage images/rpm repo)
This playbook will create a Bare Metal Type 2 server at packet.net and install a whole Nuage VNS solution to try features like Zero Touch Bootstrapping and Application Aware Routing (App classification and SLAs).
This script will do everything. When you’re done. Just add the KVM server to you WebVirtMgr and play. Let’s figure your sdwan01 is using 10.88.157.133 as Public IP address. Then you have to do the follwoing to start playing.
Create libvirt user: saslpasswd2 -a libvirt virtmgr (use the password you want)